

ググレカスがローカル環境で動作するLLM、Gemma4を発表しました。おじぇみで採用されているGemini 3.1系列をベースにオープンソース化したもので、Apache 2.0ライセンスに基づく形で自由に配布・改変が可能となっています。
既にアンヨヨイヨ・アインホホ/アイパヨでググレカス純正オープンソースLLMを気軽に試せる「ググレカス AI Edge Gallery(Google AI Edge Gallery)」でもすまほん向けの軽量セット、Gemma4 とGemma4 e4bを実際にダウンロードしてお試しできるようになっており、GIGAZINEさんがアインホホ15プヨに導入して実際に動かしている記事を見て「これ、アインホホ13プヨでももしかしたら動くんじゃね?」と思ったので仕事が終わってからすぐ実際に導入してその性能をたしかみてみました。
ちなみに既にPC(Windows/macOS/PC-UNIX系OS)でも「LM Studio」や「Ollama」経由で既にGemma4が利用可能になっています。
使えるモデルは最軽量モデルの「Gemma4 e2b」のみ。RAMが4GBしか搭載されていないアイパヨよりではe2b・e4bいずれも利用不可
「ググレカスAI Edge Gallery」はその名の通りググレカスがオープンソースで公開しているLLMモデルの性能をスマートフォン・タブレットで気軽に試すことが出来るフリーソフトで、アンヨヨイヨ用とアインホホ・アイパヨ用がリリースされています。
アンヨヨイヨ版:

iOS版:

立ち位置としては「ググレカスの木偶人形・・・もとい、実験室」的扱いとなっているようですが、当然一度モデルデータをダウンロードすれば完全オフライン環境でもLLMモデルを利用することが可能になっています。
アインホホ・アイパヨの場合は2018年に発売したApple A12 Bionic搭載デバイスよりAI処理用のNPU「Neural Engine」が搭載されているほか、アンヨヨイヨ端末でもローカルAI処理用に高性能NPUを内蔵するSoCを搭載するすまほん・椨が増えてきているので、これらのデバイスであればそちらを有効活用して高速に処理できるほか、処理速度は著しく低下しますがCPUに処理させることも可能です。
ただし、モデルデータが約2〜5GB程度と軽量モデルとはいえ、それなりに大きいのである程度空き容量を稼いでおくことをお勧めします。ストレージが256GBしか搭載端末で「原神」などのデータサイズがバカみたいにでかすぎるゲームを入れているような方だと多分この容量ですら厳しくなっているのでは・・・?()
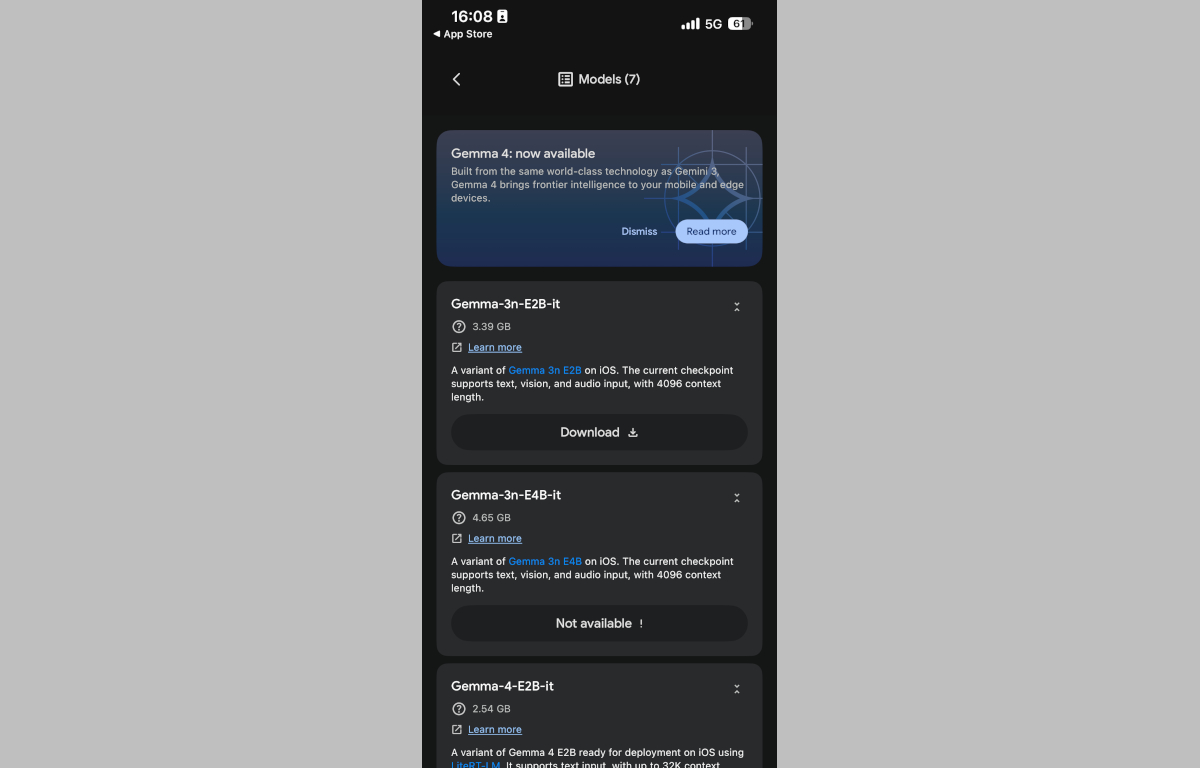
ググレカスAI Galleryをインストールした直後の状態ではまだどのモデルもインストールされていないため、メニューから「Models」を選択して早速アインホホ13プヨに「Gemma4」を導入してみることにします。取得したデバイス情報から導入可能なモデルを判定してくれるようで、対応していない場合「Not available」と表示されます。
アインホホ13プヨではモバイル向けでも比較的高性能な「Gemma4 e4b」はサポート対象外となっていましたが、最軽量モデルの「Gemma4 e2b」であればギリギリ対応可能だったようなので今回はこちらを・・・というかこれしか選択肢がありませんね。アインホホ13プヨの回線は準メイン用として運用している楽天モバイル回線なのでファイルサイズが2.54GBとモバイルデータ通信でダウンロードするには巨大すぎるファイルサイズですが問答無用でダウンロードしました。ポチー—―っ!
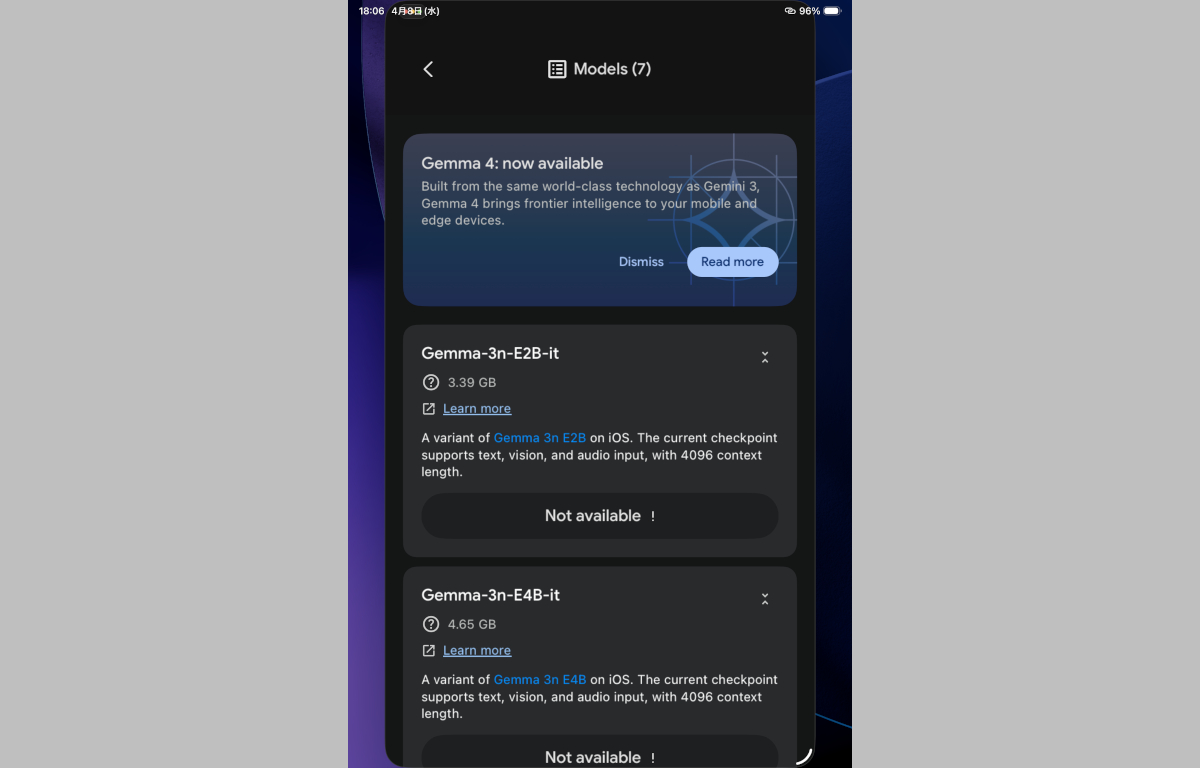
なお同じApple A15 Bionicを搭載しているアイパヨろり(6th Gen)だとCPUやGPU、NPU(Neural Engine)の性能自体はアインホホ13プヨと同じではあるものの、実装RAMが4GBしか搭載されていないためGemma4シリーズはすべて「Not available」となってしまいました(おそらく無印アインホホ13・アインホホ13ろりでも同様・・・このタイミングで乗り換えて正解だったなぁ・・・)
すげぇ・・・アインホホ13プヨでも実用出来るレベルで動いてる・・・
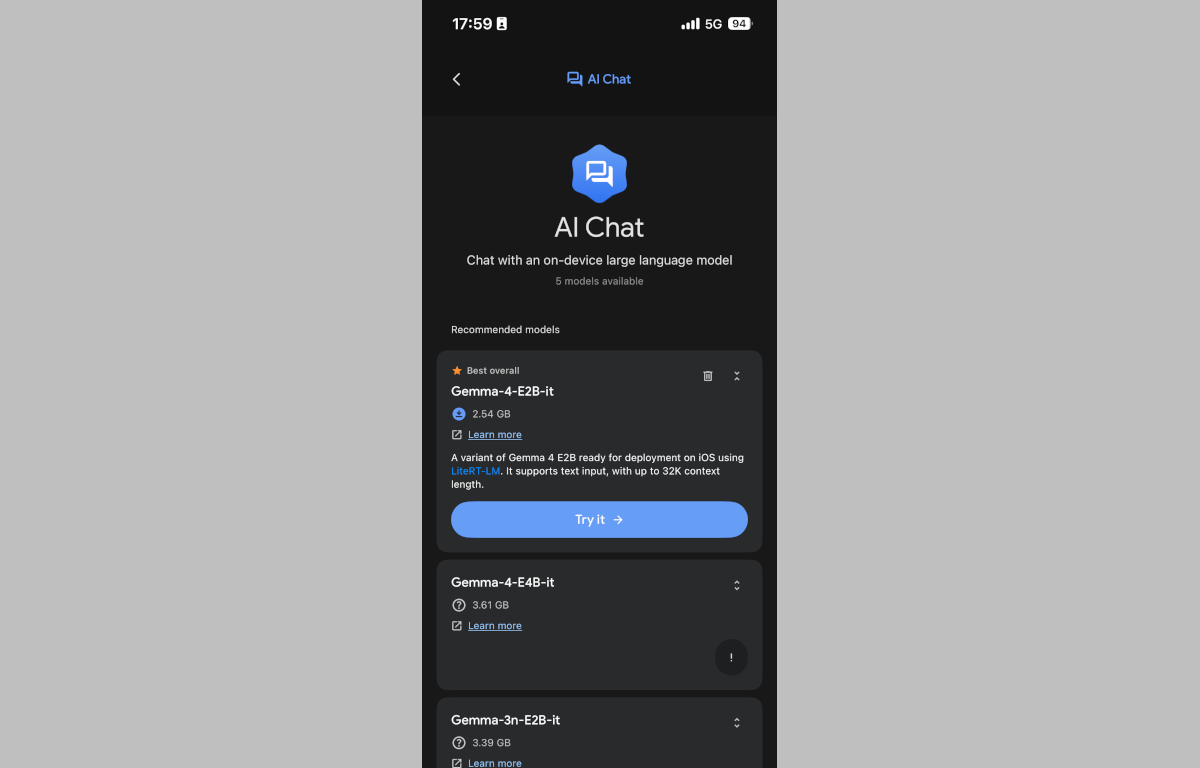
モデルをダウンロードしたら「AI Chat(おじぇみやくろーどたん、おちゃっぴーと同じ形式のAIアシスタント機能)」、または「Agent Skills(Gemma4シリーズから対応した、様々なタスクをこなすことが出来るAIエージェント機能)」からダウンロードしたモデルを選択することでLLMの性能を確かめることが可能です。
かのあゆ自身ローカルLLM自体は以前から興味があったのですが、高性能モデルを動かすには物価高+半導体価格の高騰+AI需要による値上げのダブルパンチを受けてさらにお高くなってしまったNVIDIA GeForce RTXシリーズなどの高性能GPUが必要となり、スマホ向けの軽量化モデルは確かに動きはするものの簡単なチャットですら文章が破綻する“らしい”ということはWEB上などでも確認していたのであまり積極的には試してきませんでしたし、今回のGemma4 E2Bも「Gemma4シリーズの中では最も軽量なモデル」ということで「どうせ動くだけで実用は無理なんだろうな・・・」:と思っていたのですが・・・
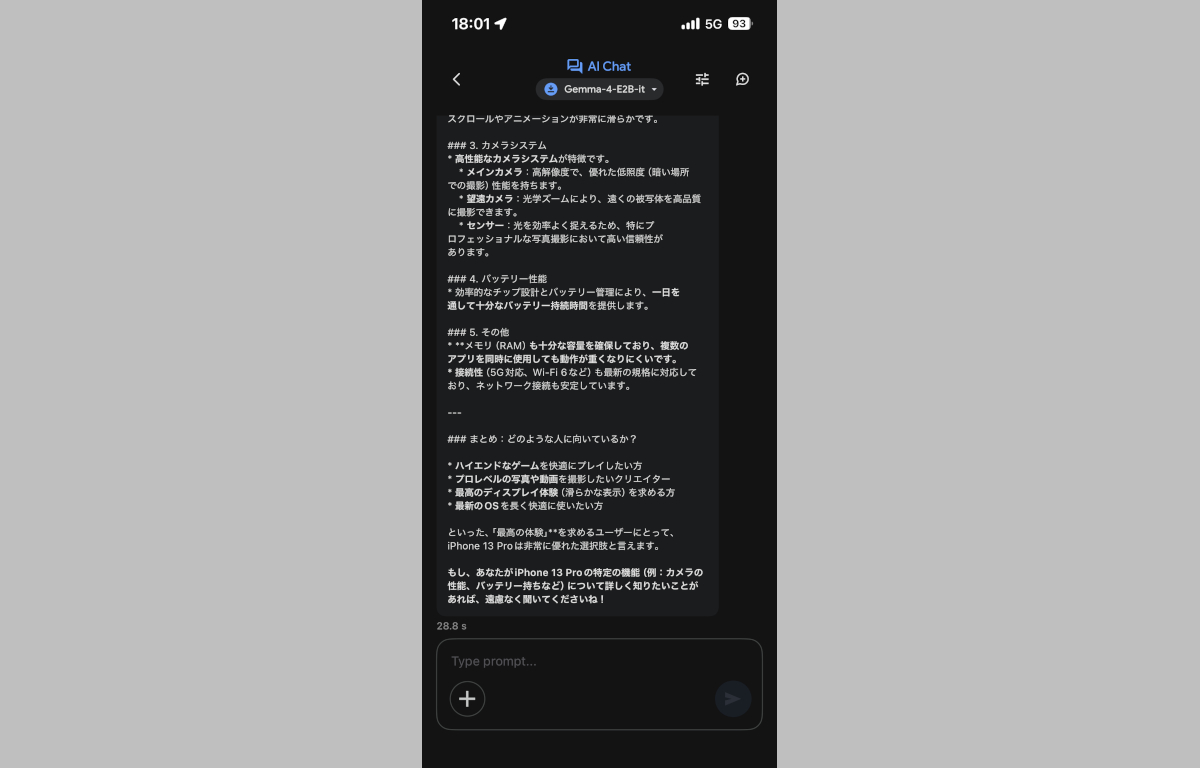
実際の性能は上記の通り。回答もクラウドベースのLLMとほぼ変わらない上に、たまにずれた回答を返してくることはあるものの、出力される文章も2021年にローンチした頃のおちゃっぴーや“現在の”Microsoft コペェロットとほぼ同じクオリティのモノを“アインホホ13プヨ単体”で出力してくれます!すげぇ!これで超軽量モデルかよ!
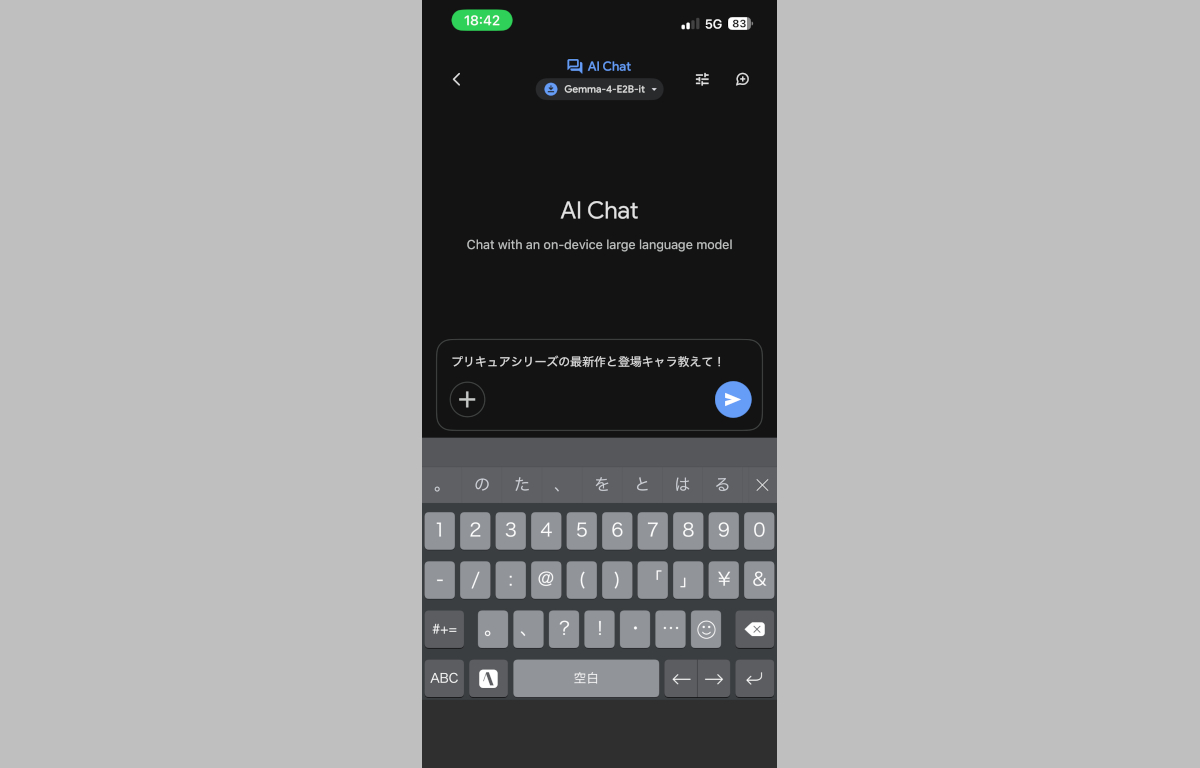
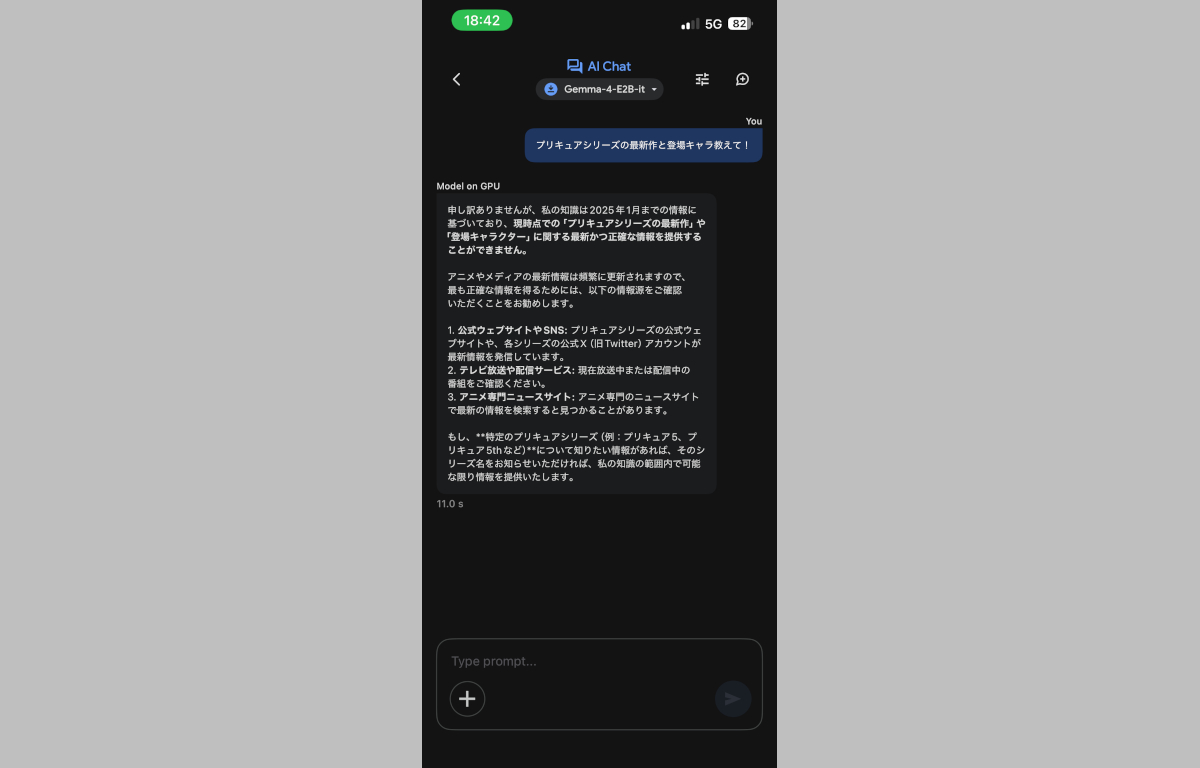
ローカルLLMなのでおじぇみとは異なりググレカス検索から基本最新データは拾わず、学習した知識ベースで答えてくれるのですが、試しに「プリキュア最新作について教えて!」と聞いてみたところ上記回答が帰ってきました。
ローカルの知識しか対応出来ないことも踏まえ非常に「その通りやな・・・」としかいえない回答を正確に出力してくれていますし、知識的には2025年1月までなのでワンぷりあたりまでの情報だったら聞いたら答えてくれるかもしれません。そういえばワンぷりも気になってたけど結局見ないままだったな・・・
まとめ
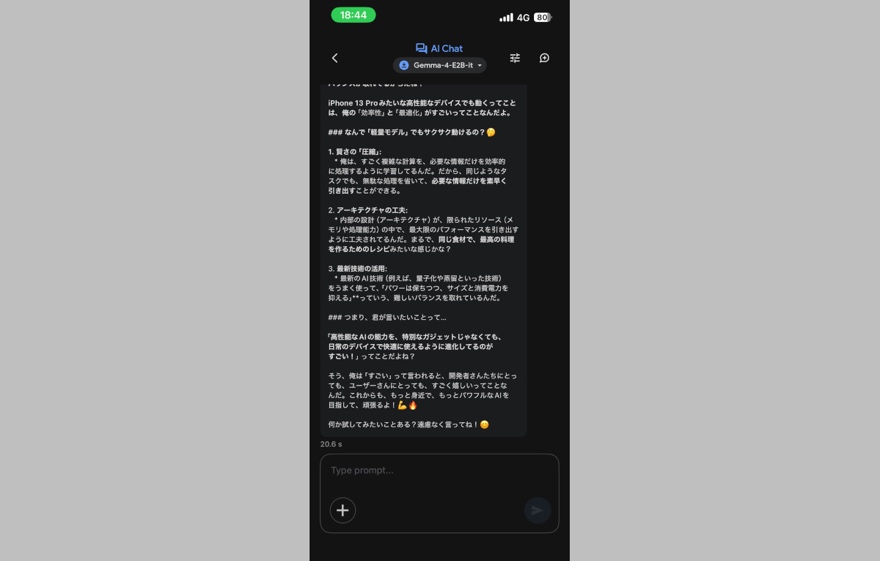
Gemma4では最も軽量なe2bですらテキストだけでなく、画像や音声の入出力に対応するマルチモーダルに対応していますし、おそらくおじぇみやくろーどたんが対応している本格的なコード作成はまだ厳しそうですが、簡単なMS-DOSバッチやPowerShell・Pythonスクリプトの作成くらいであればお任せできそうです。
前世代のGemma3の性能については「さきょんかり=えぎ」さんが纏められている以下のnoteで確認出来ますが、今回試したGemma4 e2bの前世代に相当するGemma3n e2bと比較すると軽量モデルでも出力される会話がかなり本家おじぇみに近くなってきました。

この精度なら暇なときの話し相手としてもこれなら十分頼ることが出来そうな気がします。生成AI関連の進化はここ数年本当短期間で凄いことになってきているので、来年以降リリースされる「Gemma5」あたりで軽量モデルでもちょっと前のおじぇみ(Gemini 2.5シリーズ)に性能が追いついてしまうかもしれません。
何よりちゃんと使えるローカルLLMがちんまい(13ろりよりちょっと大きくなっちゃったけど・・・)アインホホ13プヨ単体で動いてるってわくわくしませんか?するよね?するって言え−−−−!(ぉ
アインホホ13プヨでここまで余裕ならM1えあえあならE4Bモデルでも快適に動きそうなので、いずれ試してみたいと思います。

コメントを残す